Category: Programming
-

deltaTime: Corona SDK plugin for time based animations
I’ve recently published a small but handy plugin in the Corona plugin directory. The deltaTime plugin allows developers to turn regular animations into time-based animations that will play back at the same speed regardless of framerate variations. This is important because you always want to have your objects move at the same speed regardless of what the…
-

Corona SDK – The good, the bad, the great, and the downright awful
Lately I’ve been spending a lot of time developing mobile games with the Corona SDK. The idea behind it is that you code once and deploy to many targets like iOS, Android, Nook, etc. Also, Corona seems to be targeted at games and while they do have some samples of companies that did other kinds of…
-
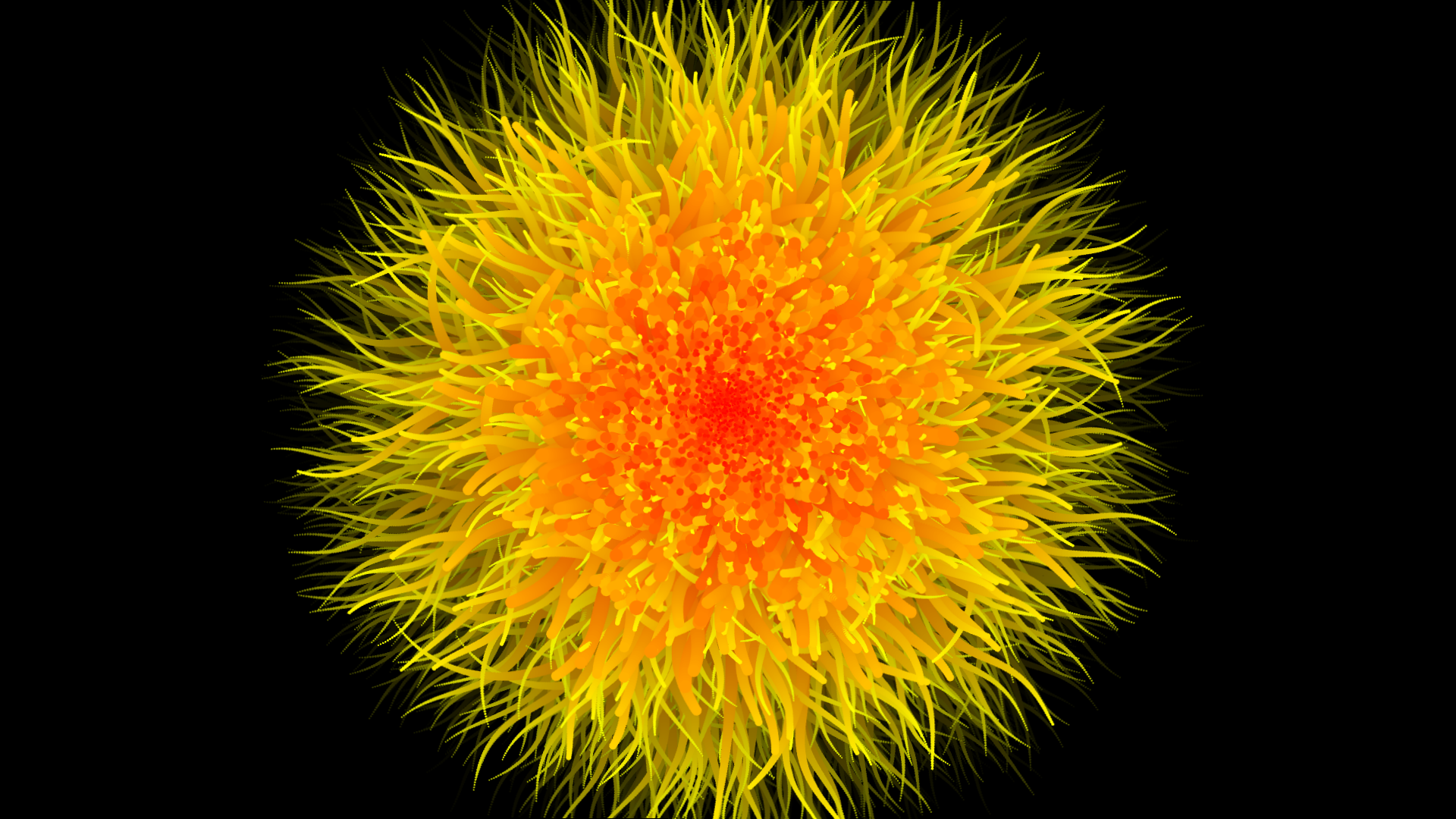
Particle based animation with openFrameworks
Continuing on with my other particle based generative art, here’s an animation I made with openFrameworks. A still:
-

Particle based generative art with openFrameworks
I’ve recently started playing with openFrameworks and I have to say I’m very impressed. Having messed with Processing previously, openFrameworks doesn’t feel too alien. It does have a steeper learning curve than Processing but it you’ve programmed C++ before it shouldn’t be long until you can whip up your first masterpieces. Last week I’ve created a very simple…
-

How to create custom TextWrangler filters with PHP
I’ve been using TextWrangler for years because it’s fast, it has all I need and best of all it’s free. Even though I don’t use it as an IDE, many times I wish it had a few features such as auto-formatting JSON strings. Fortunately, it is very easy to write custom text filters and use them…
-

Logging to Amazon’s DynamoDB from Zend Framework 2
I recently had to write an app that would run in Amazon Beanstalk. The thing with Beanstalk is that you can set some server metric to trigger automatic scaling (up or down) for your EC2 instances so you cannot count on any particular instance to be there at any time. So, any logging you do…
-

Calibrator: An Arduino library to calibrate sensors hooked to analog inputs
Once you get past your first few projects with the Arduino, you soon realize that the calibration method they show on their webpage is just a sample and cannot be used with many sensors without polluting your code with a ton of variables. So, here it is. My own take on sensor calibration library. You…
-

Hacking O’Reilly’s “Fluent Conference 2013 ” video download page
The Fluent Conference 2013 videos were out and O’Reilly was offering a nice 50% discount to early purchasers. I went to their website and made the purchase. When I looked at the download page I realized that no videos were linked to my Dropbox account (like O’Reilly does when you purchase a book from them).…
-
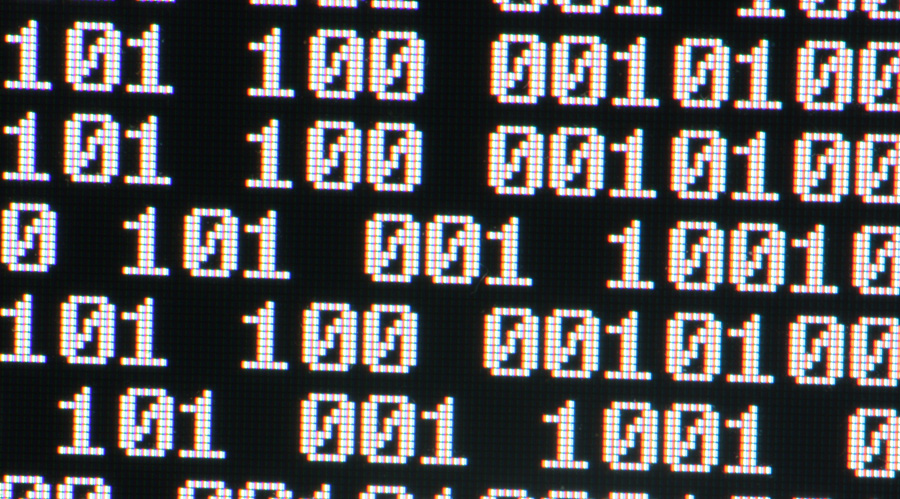
Learn how to read and write binary numbers in 5 minutes.
Over the years I’ve been asked to explain this to many people and most of the times as I was done explaining this, people would say “Huh, I thought it was harder!”. I think the reason is that when people are taught how to do this they are shown the math behind it and they…